How Heroku Works
Heroku is a cloud hosting platform focused on serving developers. Before you can get your application up and running we should discuss how the platform works.
High Level
The Heroku platform supports applications written in Ruby, Node.js, Java, Python, PHP, Clojure, and Scala. It falls in the domain of "Platform as a Service" (PaaS), allowing developers to focus on building their application while the platform deals with the intricacies of servers and deployment.
The power of Heroku is that you need to know, worry, and care very little about the systems that are used to run your application. Instead your energy goes into building your app.
Git as Transport Mechanism
There are many options for moving code between servers. Many devs have used FTP, SCP, or network shares. Heroku relies on Git.
Why Git?
Heroku made a big bet on Git back in the mid-2000s, and since then Git has come to dominate modern application development. It’s the Source Control Management (SCM) option chosen for most new applications.
Heroku as Git Remote
If you’re using Git, then shipping code to Heroku is easy. A Git repository typically has one or more remotes. These often have names like origin and point to the places where you host and share code with colleagues, like GitHub.
You can think of Heroku as a big Git server. When you "create" an application, the end result is that you have a new Git remote that you can push code to.
Just Like Any Other Remote
The SSH-style URL for an application looks like this:
1
| |
When you create an app on Heroku, the toolbelt will add a remote named heroku with your app’s correct URL. If you wanted to do it manually, however, it’s just the same as any other Git remote:
Terminal
$
| |
Now It’s Just Git
Once Heroku is a remote for your repo, you can:
- Push code
- Pull code
- Use Heroku as the place where you store your code (instead of GitHub)
Typically, though, you’re only going to exercise option 1.
Building a Slug
Once the code is transferred, Heroku starts building a slug. A slug is a compressed archive containing your application code, configuration, and any dependencies (like external libraries).
This slug is then a self-contained, ready-to-run version of your application. It just needs to be started.
Dynos Run Slugs
You can think of a dyno like a single-purpose computer. A dyno can take a slug and run it, making the application available to the world.
One Dyno, One Slug
A single dyno can only run one slug. You can use multiple processes and threads to have multiple things happening at once, but a dyno cannot be shared by multiple slugs.
One Slug, Many Dynos
The converse is not true. That slug is just a zipped up version of your application. It can be copied to and booted by multiple dynos. To support real-world traffic, many applications utilize eight or more dynos all running copies of the same slug.
Responding to Requests
A slug is built and started up on one or more dynos, then what?
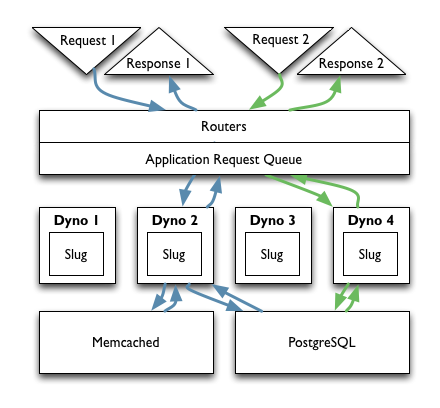
A Request Arrives at the Routers
A request comes into Heroku’s Routers and, based on the domain specified in the request, the router figures out that it belongs to your application.
Once Heroku knows that the request belongs to your application it needs to be distributed to a dyno. There are several approaches to distributing work among multiple workers, which is the pattern in place here with dynos, each with their own advantages and drawbacks.
Heroku’s chosen to randomize requests as they come through the routers due to the low coordination overhead. When a request comes in you don’t know and shouldn’t care which of your dynos it gets routed to. The next request will likely get routed to a different dyno, and that shouldn’t matter to your application.
External Data - PostgreSQL
Most web applications need to store data in a traditional database, an in-memory store, on the filesystem, or some combination thereof.
If you have multiple dynos all responding to requests, that can be tricky. If my first request goes to Dyno A, stores data, then my next request goes to Dyno B, will the data be there?
Heroku separates the concept of the data store from the web application. If you were setting up a VPS you might run the application and database on the same machine and communicate over UNIX sockets, but you could also use TCP/IP.
Heroku hosts database instances and in fact provisions an instance of PostgreSQL for your application when you first create it. That database instance is accessible over TCP/IP, so all your dynos can access it simultaneously.
Heroku stores the location of the database in environment variables accessible to all your dynos, so once one dyno can reach the database then all of them can. You can scale up dynos with no additional configuration.
The same approach holds true for the filesystem. Heroku recommends you consider the dyno’s filesystem to be "ephemeral". You can write to it, but those writes won’t persist across dyno restarts. You should thus think of dynos as stateless.
If you need to store files, push them out to Amazon’s S3. Put the credentials in your application configuration and they’ll be shared by all dynos.
External Data - Memcached
Need an in-memory store like Redis or Memcached? Install one of the available add-ons and all the dynos can reach it via the same approach – TCP/IP connections specified in the environment variables.
Recap
- You transfer code to Heroku by using
git push - Heroku builds an archive of your ready-to-run application called a slug
- A slug gets copied to and run on one or more dynos. The more dynos you run, the more traffic you can support.
- Requests come in to Heroku’s Routers and are dispatched to your application
- All dynos can share external data so you don’t care which dyno is actually serving the request
References
- How Heroku Works on Heroku’s Dev Center
- Heroku Architecture on Heroku’s Dev Center
