Performance
Caching Data
There are two hard things in computer science: naming things, cache invalidation, and off-by-one errors. Let’s talk about that second one.
Caching is difficult to get right, but Rails provides you with some excellent tools to help make it easy. In this tutorial, we’ll look at how to pre-calculate data so requests utilizing that data can respond quickly.
Setup
Get the Blogger project from GitHub and run setup procedures:
1 2 3 4 5 | |
All existing tests should pass. Optionally, run the tests continuously while developing by running guard
Simple Data Caching
Terminology
Computers compute. Sometimes, they do a lot of computing. Sometimes, they need to do so much computing that it takes a really, really long time. But we want our sites to be fast. What do we do?
The answer is a cache. A cache is a temporary storage place. In software, the cache is typically used to store data you want fast access to, but the cache is not the primary storage place.
The database is meant to be your durable, long-run data storage. You should use a cache in such a way that if it gets totally deleted you haven’t lost any data of value.
An empty cache is "cold" and as we calculate and store data values we’re "warming" it. If we try and load a piece of data from the cache and it’s not that, that’s a "cache miss". If the data is there when we want it, that’s a "cache hit".
When our underlying database data changes and the cache entries need to be removed we’re invalidating them.
The problem
We’re working with the blog application you may have used in previous
tutorials, but if you haven’t, it’s pretty straightforward. Authors write
Articles that have Comments and Tags. We’re going to add some caching to
the admin dashboard to improve its performance.
"If you can not measure it, you can not improve it." - Lord Kelvin
When you have a web application, statistics on its usage are important. They can help you optimize conversions, plan new content based on what’s been popular on the past, and tons of other things.
Let’s load up the site and check it out:
Terminal
$
| |
If you open http://localhost:3000 in your browser, you’ll see something like this:
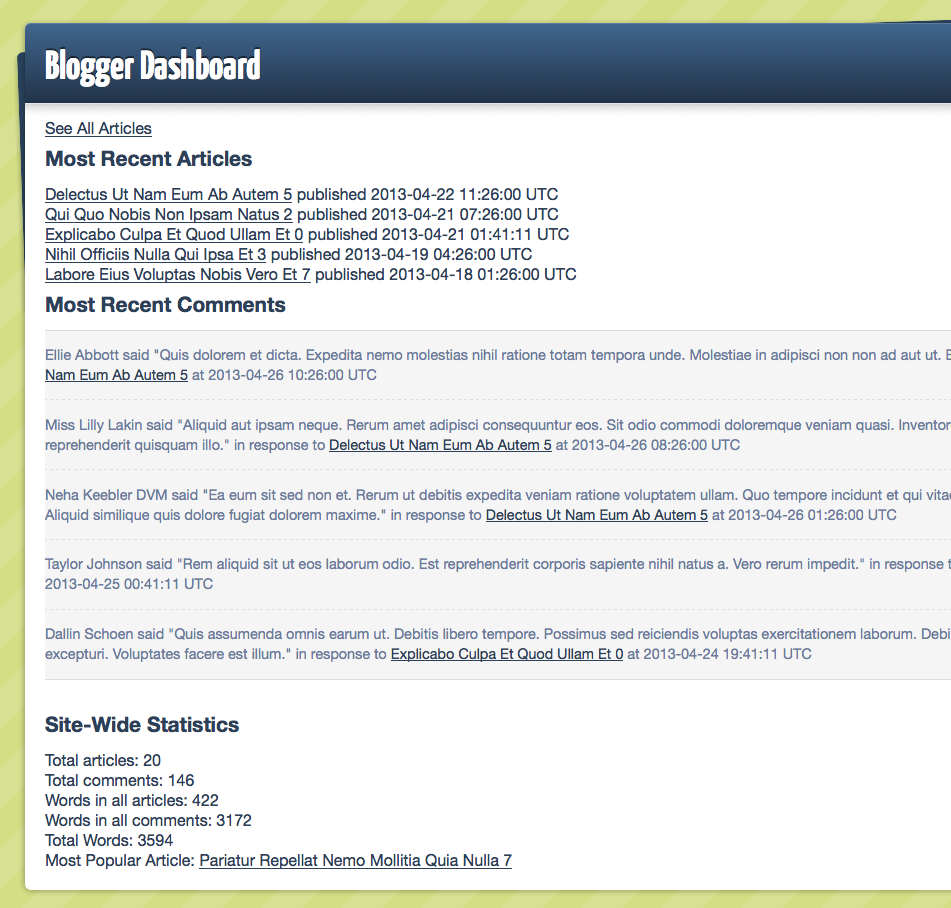
That part at the bottom is what we’ll be improving upon. We collect a number of statistics about the articles, comments, and the number of words in the sum of them. This page renders pretty quickly at the moment, but as the number of articles and comments goes up, it can get really slow.
Let’s change things so that we can see this difference. Open up db/seeds.rb and increase the number of objects generated:
1 2 3 | |
Then, re-build the database:
Terminal
$ $ | |
Now load up the site again, and it should feel…slow.
1 2 | |
Five seconds. Hit refresh. Another five seconds. This situation is unacceptable, so let’s fix it.
An Experimental Approach: Class Instance Variables
The easiest possible thing that we can do is to Just Use Ruby.
Finding the Slowness
Let’s check out the DashboardController, where the calculation is done:
1 2 3 4 5 6 7 8 9 10 11 12 | |
All the logic is pressed down to the models. Let’s then check out
Article.total_word_count:
1 2 3 | |
We load up all the articles and loop through them calling word_count on each. This works, but will be super slow. We re-run the calculation on each new request!
Memoization
We can use memoization to improve this situation. Memoization is a technique where
a method is made faster by not repeating cacluations that were previously
done. In Ruby, this is most commonly accomplished through instance variables. For instance, with the total_word_count method we can add an instance variable in front of the calculation:
1 2 3 | |
How Memoization Works
Now, the first time we use total_word_count, it will save the answer into the
@total_word_count variable. On subsequent calls the ||= will return the previously-calculated data instead of re-performing the calculation.
Note that since the instance variable is created inside a self. class method, it is stored on with the class itself. Remember that classes in Ruby are instances of the Class class. If you were creating a normal instance variable in an Article instance method it would only be attached to that instance of Article which gets wiped away between requests.
But the class is not re-loaded between requests. Thus the class instance variable will still be there for the subsequent requests.
Memoizing Other Methods
Go ahead and use the same technique for the other methods called from the
DashboardController#show.
Testing the Results
Start up your server again with rails s and load the dashboard page. You should see output in your server log similar to this:
1 2 | |
Then hit refresh in your browser and observe something like this:
1 2 | |
Whoah! Here’s a diff of all changes made in this experiment:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | |
Just three lines changed, adding three variables, and we went from 4,000 ms to 43 ms! So we’re done, right?
Memoization Means Problems
Not so fast. The first page load still takes four seconds. And it’ll take four seconds every time we restart our server, as well. That’s often not good enough.
More importantly, our cached values never expire! When we add a new article or comment the old data will still be memoized. The dashboard will never change! We could chase around our code and find every place that changes an article or a comment and tell it to clear the cached values. But you’ll miss one (or more) as the application grows and your cache won’t work properly.
We need a better strategy.
Using Rails.cache
There are software tools called ‘key/value stores’ that can tackle this exact sitaution. From the name, you can infer that a key/value store… stores keys and values.
You know how to use hashes in Ruby. Think of a key/value store as a big-hash-as-a-server. It’s persistent and can be shared by multiple processes or applications.
Starting with Redis
There are multiple key/value stores, and so Rails provides an interface to use any one you want. Just remember the Rails API, and you can use Redis, Memcached, or another store that you may fancy.
Let’s explore Redis which is an excellent key/value store.
You need to follow the instructions for installing and configuring Redis to follow this part of the tutorial.
Keys & Values in Ruby
First let’s look at a simple Ruby Hash:
IRB
|
Easy, right?
Rails.cache
From the Rails console:
IRB
|
Your data is stored in the cache.
Redis Console
You can connect to Redis directly to inspect keys and values:
Terminal
$ | |
That "ns:count" there shows we have a count key in the ns namespace.
Using fetch
If you were to implement it right now, you’d probably do something like this:
1 2 3 4 5 6 7 8 9 10 | |
Check to see if we have it cached, if not, calculate and store it, then return the answer. It’ll work.
But the #fetch method will make your life much easier. It’s a method available on any Hash in Ruby:
IRB
|
We created the sample hash with no keys, so asking for sample["count"] would normally return nil. But with #fetch you can pass a block which provides a default value. Since the "count" key was not found, 5 was returned.
But, it doesn’t store that value. So if you now ask for the key again the normal way:
IRB
|
It doesn’t actually save the value into our Hash. Bummer.
Rails Cache & #fetch
However, Rails.cache is not a normal Ruby hash. It’s a specialized class which not only implements #fetch, but also stores the value:
IRB
|
Awesome! Now, we can write our method in a much simpler way:
1 2 3 4 5 | |
Keys Must Be Unique
One small note: you may notice that we’ve added comment_ to the front of our
key. This is because we have a total_word_count for both articles and
comments. The keys in a hash much be unique.
Cache Data Must Be Simple
Check out the #most_popular method with memoization:
1 2 3 | |
This stored a Article object in @most_popular.
Your data cache (Redis) is not Ruby. It doesn’t know about Article objects. It only deals with strings, integers, and a few other simple data types. You can try to serialize your Article instance into a string and deserialize it later, but you’re going to have a bad time. Serialization causes lots of new problems.
Only store those simple data types into the cache. For most_popular, you can store just the id of the most popular article in the cache. Then, when the method is called, find the id and execute a single database query to get the actual article.
1 2 3 4 5 6 7 | |
Implement It
Go ahead and implement these tactics for all three of our methods that need caching. When you hit the server, the very first page load will be slow, then all the rest should be fast. Restart your server, and it should still be fast. Your cache is now warm.
However, that first page load is still slow. Not cool. And if we add a new
Article or Comment, it doesn’t update the data because our cache hasn’t been expired.
Explicit Cache Expiration
When do we need to recalculate the data? Whenever a comment or article is added, removed, or changed.
Using Rails Callbacks
Let’s take advantage of Rails’ callbacks system to invalidate our cache when those objects are changed.
Creating InvalidatesCache
Create a file app/models/invalidates_cache.rb with these contents:
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
This module makes use of the included method from ActiveSupport::Concern. All the code between the do and end will be executed in the context of the including class, just as if you’d written these lines in the model class itself.
Using InvalidatesCache
Open your Article and Comment models and add the following inside the class definition. Typically includes are done at the top of the class, so it’d look like…
1 2 3 4 | |
Now, when we make a new Article or Comment (or update it), the entire cache gets
blown away.
Observing the Behavior
Experiment with it in the Rails console:
IRB
|
Blowing away the entire cache is quite expensive because now it’s totally cold. Every subsequent request that uses cached data will miss until it’s all recalculated and stored.
Fine-Grained Expiration
To do this right we need to know exactly which keys should be invalidated when a record changes. We need to keep track of which calculation goes with which key, and update them accordingly.
We also need to know which calculations depend on each other. For example, the total words calculation relies on both articles and comments, but the most popular article calculation only relies on articles.
Caching is hard and for this kind of usage there are no easy answers.
